
机器学习的应用
- 数据库挖掘。机器学习被用于数据挖掘的原因之一是网络和自动化技术的增长,这意味着,我们有史上最大的数据集比如说,大量的硅谷公司正在收集web上的单击数据,也称为点击流数据,并尝试使用机器学习算法来分析数据,更好的了解用户,并为用户提供更好的服务。这在硅谷有巨大的市场。再比如,医疗记录。随着自动化的出现,我们现在有了电子医疗记录。如果我们可以把医疗记录变成医学知识,我们就可以更好地理解疾病。再如,
- 计算生物学。还是因为自动化技术,生物学家们收集的大量基因数据序列、DNA序列和等等,机器运行算法让我们更好地了解人类基因组,大家都知道这对人类意味着什么。再比如,工程方面,在工程的所有领域,我们有越来越大、越来越大的数据集,我们试图使用学习算法,来理解这些数据。另外,
- 机械应用。有些人不能直接操作。例如,我已经在无人直升机领域工作了许多年。我们不知道如何写一段程序让直升机自己飞。我们唯一能做的就是让计算机自己学习如何驾驶直升机。
- 手写识别。现在我们能够非常便宜地把信寄到这个美国甚至全世界的原因之一就是当你写一个像这样的信封,一种学习算法已经学会如何读你信封,它可以自动选择路径,所以我们只需要花几个美分把这封信寄到数千英里外。
机器学习
在机器学习的历史上,一共出现了两种定义。
1956 年,开发了西洋跳棋 AI 程序的 Arthur Samuel 在标志着人工智能学科诞生的达特茅斯会议上定义了 “机器学习” 这个词,定义为,“在没有明确设置的情况下,使计算机具有学习能力的研究领域”。
1997 年,Tom Mitchell 提供了一个更现代的定义:“如果用 P 来测量程序在任务 T 中性能。若一个程序通过利用经验 E 在 T 任务中获得了性能改善,则我们就说关于任务 T 和 性能测量 P ,该程序对经验 E 进行了学习。”
例如:玩跳棋。
E = 玩很多盘跳棋游戏的经验
T = 玩跳棋的任务。
P = 程序将赢得下一场比赛的概率。
分类
一般来说,任何机器学习问题都可以分配到两大类中的一个:
有监督学习 supervised learning 和无监督学习 unsupervised learning。
简单的说,监督学习就是我们教计算机去做某件事情,无监督学习是我们让计算机自己学习。
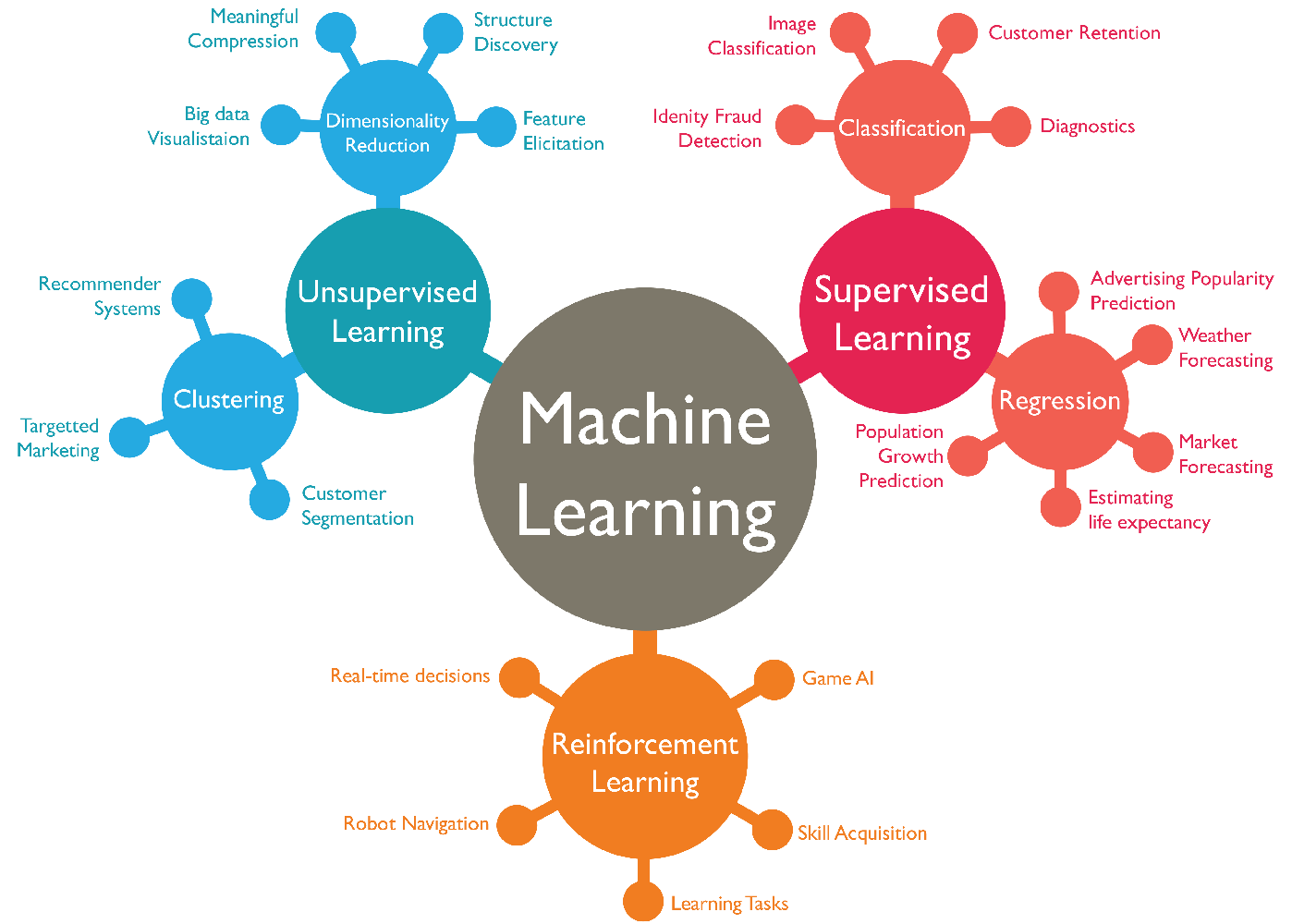

监督学习
在监督式学习中,首先有一个数据集,并且已知正确的输出是什么,且输入和输出存在关联。 监督学习问题分为“回归 Regression”和“分类 Classification”问题。
在回归问题中,我们试图预测连续输出中的结果,这意味着我们试图将输入变量映射到某个连续函数。例如给定一个人的照片,根据照片预测年龄,这就是一个回归的问题。

在分类问题中,我们试图预测离散输出中的结果。换句话说,我们试图将输入变量映射到离散类别中。例如给予患有肿瘤的患者,我们必须预测肿瘤是恶性的还是良性的。

无监督学习
无监督学习使我们能够很少或根本不知道我们的结果应该是什么样子。我们可以从数据中得出结构,我们不一定知道变量的影响。 我们可以通过基于数据中变量之间的关系对数据进行聚类来推导出这种结构。 在无监督学习的情况下,没有基于预测结果的反馈。无监督学习可以分为“聚类”和“非聚类”。
聚类:获取1,000,000个不同基因的集合,并找到一种方法将这些基因自动分组成不同变量的相似或相关的组,例如寿命,位置,角色等。

非聚类:“鸡尾酒会算法”,允许您在混乱的环境中查找结果。 (即在鸡尾酒会上识别来自声音网格的个人声音和音乐)。
